
high-throughput sequence analysis cluster enables next-generation personalized treatment development. These infrastructures are optimized to ingest enormous sequence datasets and identify key biomarkers. By leveraging advanced algorithms and domain-aware pipelines, they accelerate discovery across genomics and translational research.
High-Throughput Bioinformatics Compute: Scalable Server Solutions
Next-generation sequencing generates large data volumes that necessitate elastic computational platforms. To effectively process and analyze this growing data, scalable computing servers are essential.
- Dynamic scaling of CPU, memory, and storage is a hallmark of modern bioinformatics servers.
- Concurrent processing across many cores and nodes reduces runtime for genome-wide tasks.
- Servers power tasks from raw read processing to variant prioritization and downstream biological modeling.
Simultaneously, cloud platforms have democratized access to powerful bioinformatics compute and storage.
Specialized Cloud Environments for Genomic Computation
Growth in sequencing throughput has accelerated the need for elastic, tool-rich bioinformatics clouds. Cloud-based infrastructures offer flexible compute pools, optimized pipelines, and integrated data management.
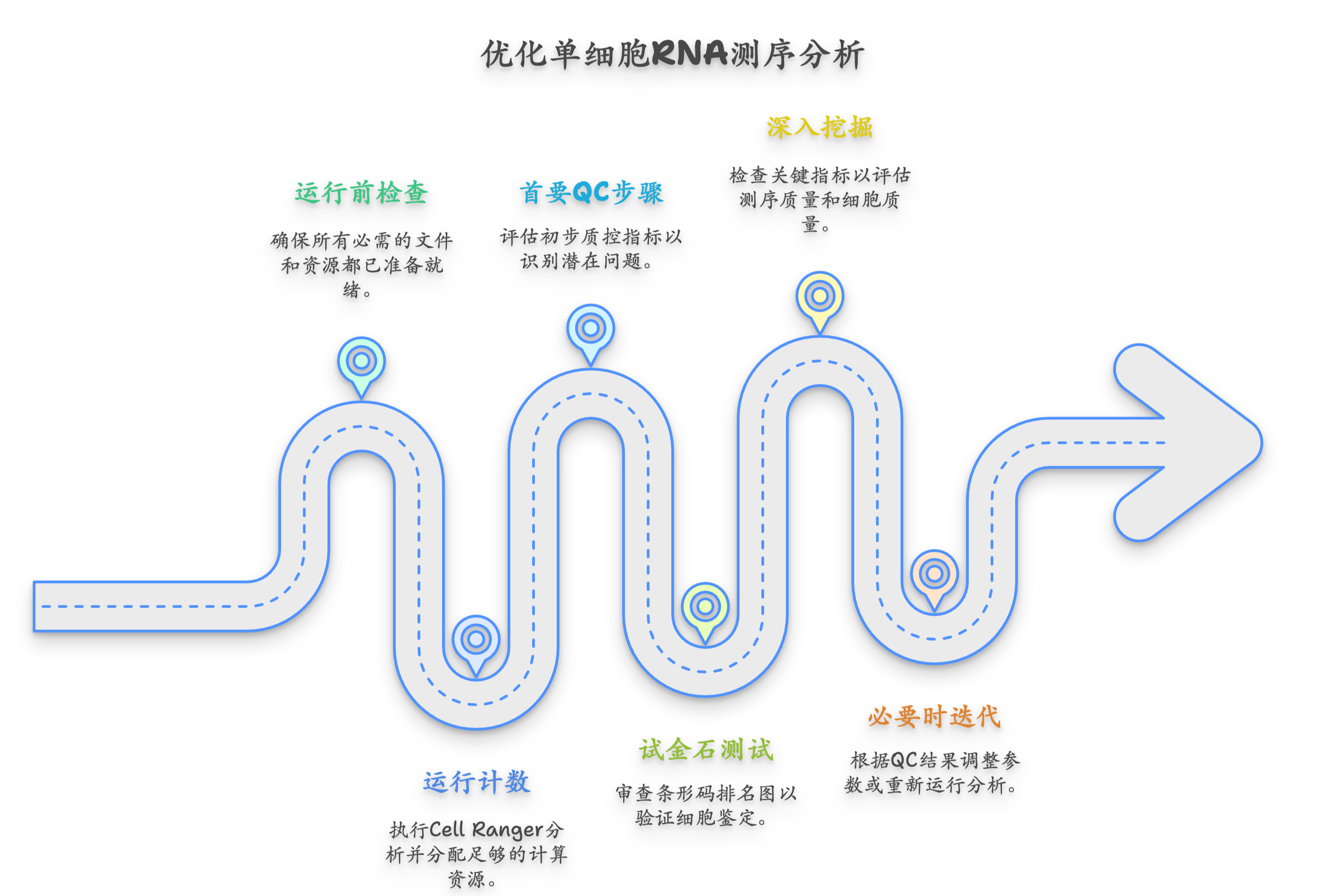
Cloud and Distributed Solutions for Extensive Bioinformatic Analyses
High-complexity analyses in modern bioinformatics depend on elastic, high-throughput compute. Traditional infrastructure can be expensive to scale and challenging to maintain for evolving pipelines.
With on-demand cloud resources, researchers can perform large-scale variant discovery and population analyses.
Elastic cloud services help optimize budgets and remove infrastructure bottlenecks while promoting collaborative workflows.
Specialized Cloud Architectures Shaping Bioinformatics' Future
As research complexity increases, cloud vendors deliver specialized stacks that accelerate discovery and compliance. Platforms deliver integrated analytics, secure data governance, and scalable compute optimized for omics workloads.
Moreover, the intrinsic scalability of cloud computing allows rapid resource changes on demand, democratizing access to advanced bioinformatics and empowering researchers globally.

Streamlining Bioinformatics Workflow with On-Demand Servers
When workflows require bursts of compute, on-demand servers present a cost-effective, rapid solution. Avoiding on-prem hardware reduces administrative overhead and shortens time-to-result for analyses.
Moreover, on-demand servers often arrive pre-configured with essential bioinformatics software stacks like alignment tools and statistical pipelines, streamlining the workflow. Less time spent on setup equals more time for analysis, validation, and collaborative interpretation.
On-Demand Bioinformatics Services for Scalable Exploration
aaS clouds combine compute, storage, and domain tools to lower barriers for large-scale biological exploration. Such platforms provide the compute and tooling necessary to turn data into biological and clinical insight.

- Managed bioinformatics services scale with project needs to facilitate high-throughput analysis.
- Cloud platforms make it easier to collaborate on code, workflows, and annotated datasets across labs.
- State-of-the-art analytics transform raw data into testable biological hypotheses and clinical leads.
Precision Medicine Empowered by Scalable Bioinformatics Analysis
Growing multi-omics and clinical datasets create opportunities to tailor therapies to patient-specific profiles. Bioinformatic analysis servers extract meaningful insights from complex datasets using sophisticated algorithms to predict disease risk, tailor treatment plans, and monitor patient responses. Real-time, interpretable results from servers accelerate clinical decision support and individualized interventions.
Transformative Insights from Scalable Bioinformatics Computing
High-performance computing uncovers structure-function relationships and regulatory networks from omics data. Systematic computational processing finds correlations and causal signals across vast biological datasets.
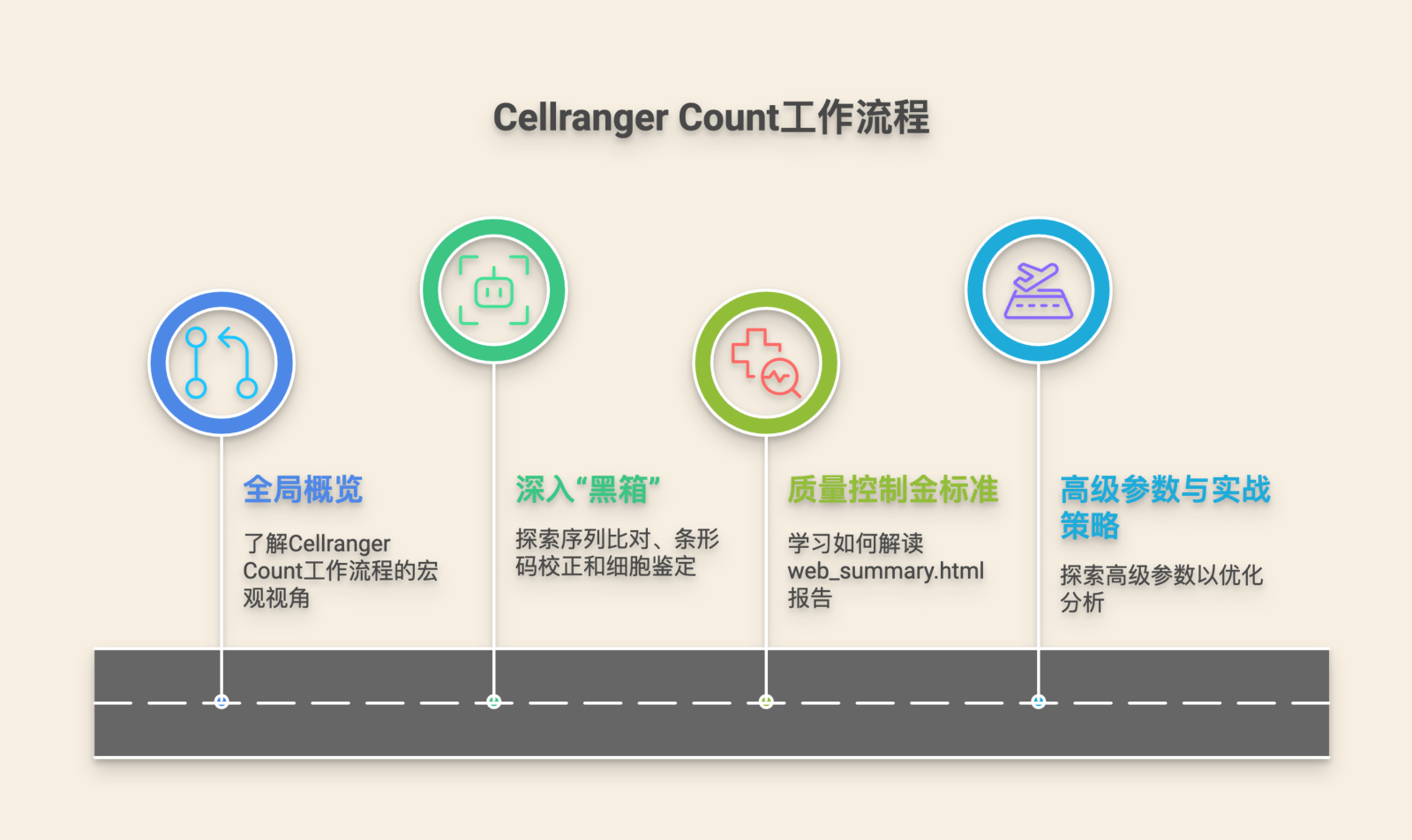
To decode complex biology, researchers depend on algorithmic, reproducible, and scalable computational frameworks.
Future-Proof Bioinformatics Infrastructure for Scalable Science
The data-intensive nature of bioinformatics calls for infrastructures that scale while maintaining reproducibility. By integrating parallel processing, GPU acceleration, and optimized storage, next-gen systems shorten analysis cycles.
- Cloud solutions enable rapid scaling of cores, memory, and storage to align with research timelines.
- Dedicated bioinformatics software ecosystems are refined to improve accuracy and reproducibility.
These platforms promote collaborative science, supporting fast iteration and cross-team data sharing.
A Robust Bioinformatics Toolset for Scientific Exploration
Comprehensive platforms provide the instruments researchers need to convert data into biological knowledge. The toolset integrates aligners, gene finders, phylogeny builders, and modeling suites backed by current databases. An easy-to-use interface and integrated resources let biologists and bioinformaticians explore data without heavy admin overhead.